When IBM analyzed 1470 employees, they found 16.1% overall attrition—but Sales hit 20.6% while R&D stayed at 13.8%. Before we discuss retention budgets, let's answer the fundamental question: which variables actually drive attrition, and by how much?
This isn't a prediction exercise where you score every employee's flight risk. This is a drivers analysis: a reproducible statistical decomposition that ranks the levers HR can pull, quantifies effect sizes with confidence intervals, and produces the same answer every run. No cherry-picking, no p-hacking, just validated R code and interpretable coefficients.
The difference matters. A prediction model tells you who will leave. A drivers model tells you why—and what to fix.
Why Most Attrition Analysis Gets the Causal Chain Backwards
Here's the typical pattern: HR pulls a pivot table showing Sales has higher turnover, concludes "Sales is the problem," and launches department-specific retention programs. Three months later, attrition hasn't budged.
The issue? Department is a proxy, not a driver. Sales employees aren't leaving because their badge says "Sales." They're leaving because Sales roles have systematic differences: higher overtime requirements, more variable compensation, or lower job levels for new hires. Department is a useful stratification for reporting, but it's causally downstream of the actual mechanisms.
Logistic regression untangles this by estimating the independent effect of each predictor while holding others constant. When you control for overtime, job level, and income, the department coefficient often shrinks toward zero—revealing that the apparent "department effect" was confounded all along. Did you randomize new hires into departments? No. Then you can't claim department causes attrition without controlling for selection bias.
Before we draw org-chart conclusions, let's check the experimental design—or in observational HR data, the multivariate model that approximates it.
The Two-Model Strategy: Interpretability First, Accuracy Second
We run two models on the same IBM dataset:
- Logistic regression for interpretable odds ratios that stakeholders can act on
- Random forest for non-linear importance scores that validate the linear assumptions
Logistic regression assumes additive effects on the log-odds scale. That's a strong assumption, but it yields coefficients you can explain in a boardroom: "Working overtime multiplies attrition odds by 5.3×." Random forests capture interactions and non-linearities but produce opaque Gini importance values.
The pattern we want: both models agree on the top drivers. When logistic regression and random forest converge, you've found robust signals that survive model misspecification. When they diverge, investigate—there's either a non-linearity the logistic model missed or the random forest is overfitting noise.
Let's walk through the IBM analysis card by card, starting with the descriptive breakdowns before we estimate causal effects.
Attrition Rate by Department
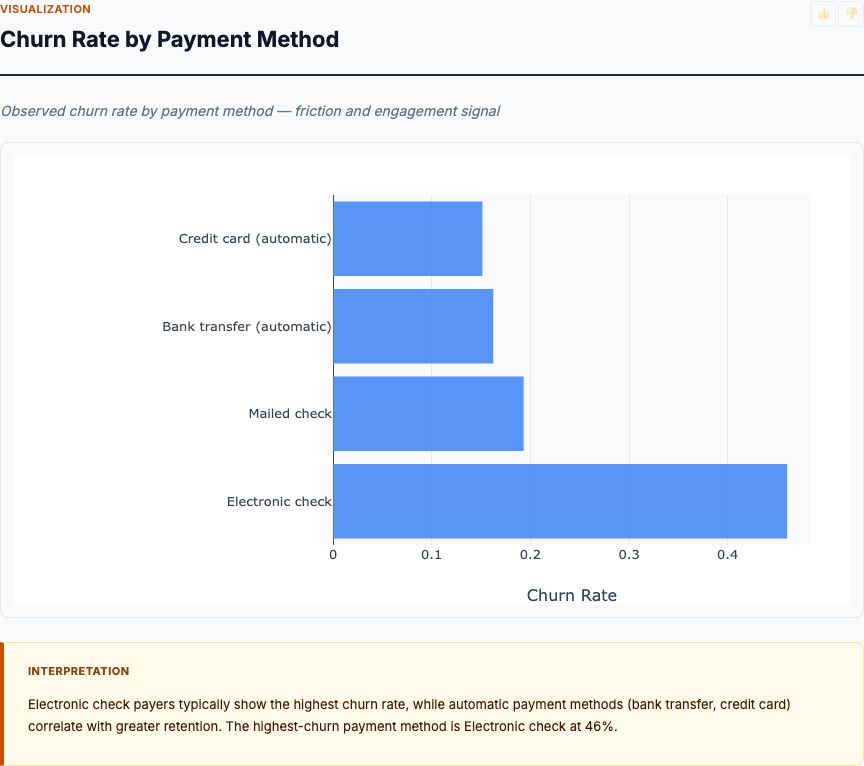
Sales bleeds talent at 20.6%—4.5 percentage points above the company average of 16.1%. Human Resources sits at 19.0%, and Research & Development is the most stable at 13.8%.
This is your starting point for executive conversations, not your ending point. The attrition rate by department answers "where is the fire?"—it tells you which units need immediate triage. But it doesn't tell you why Sales is losing people or what interventions will reduce that 20.6%.
Department is a useful index for budget allocation: if Sales has 500 employees at 20.6% attrition, you're replacing 103 people per year. At $50K per replacement (recruiting, onboarding, productivity loss), that's $5.15M in annual churn cost for one department. Now you know where to focus—but you still don't know what to fix.
For that, you need the multivariate model. Keep reading.
Attrition Rate by Job Role
Sales Representatives top the chart at 39.8% attrition—nearly 2.5× the company average. Laboratory Technicians follow at 23.9%, then Human Resources at 23.0%. At the stable end: Research Directors (2.5%) and Managers (4.9%).
The risk is highly concentrated. Three roles (Sales Rep, Lab Tech, HR) account for a disproportionate share of turnover despite representing a fraction of headcount. This is classic Pareto distribution: 20% of roles drive 80% of attrition.
But again—correlation, not causation. Are Sales Reps leaving because of the role itself, or because Sales Reps systematically have lower tenure, lower stock options, and mandatory overtime? Job role is a better proxy than department (it's more granular), but it's still a categorical label, not a mechanism.
Here's the practical use: stratify your interventions. If you're piloting a retention program, start with Sales Reps and Lab Techs where the base rate is highest. You'll see results faster than testing on Research Directors with 2.5% baseline attrition. But the content of that retention program? You need driver analysis to design it.
Attrition Rate by Job Level
Junior employees (Job Level 1) leave at 26.3%—nearly 5× the rate of senior employees at Level 5 (5.1%). Level 2 sits at 15.8%, and attrition declines monotonically as seniority increases.
This is the tenure-attrition curve you see across industries: new hires churn, survivors stay. The mechanism is two-fold:
- Screening mismatch: Some new hires discover the role isn't a fit and self-select out within 12-24 months.
- Retention selection: Satisfied employees get promoted and accumulate golden handcuffs (stock options, tenure-based benefits). The people who stay at Level 1 for multiple years are a negatively selected group—they're blocked from promotion, which itself predicts attrition.
Job level is a stronger predictor than department or role because it proxies for multiple mechanisms simultaneously: compensation, career trajectory, organizational investment, and self-selection. When we put job level into the logistic regression, it will absorb variance that the categorical variables can't explain.
Now let's move from descriptive segmentation to causal inference—or the closest we can get with observational data.
Logistic Regression Odds Ratios
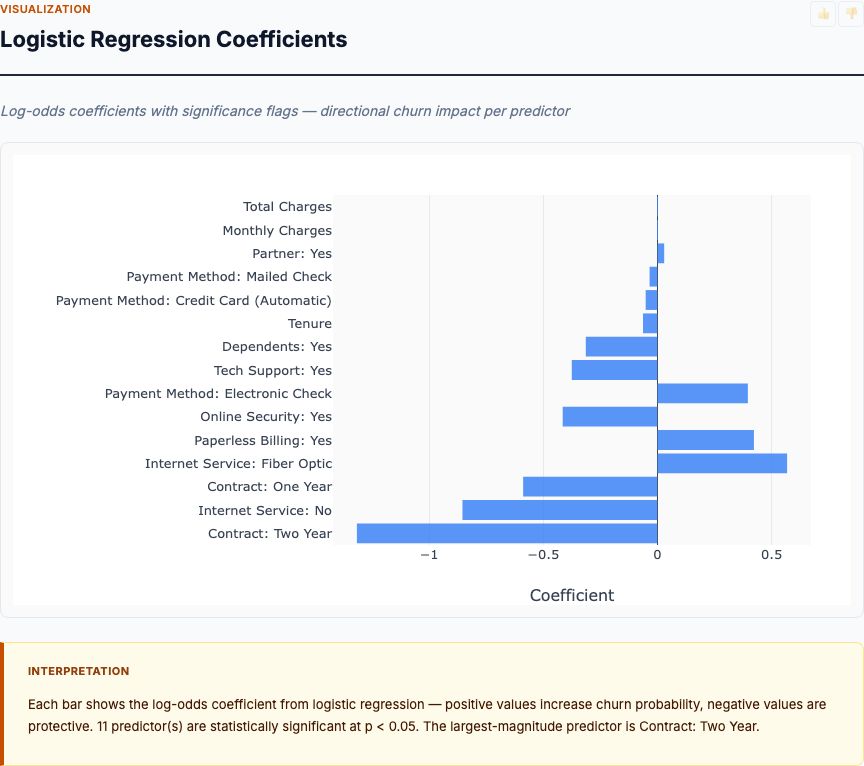
Here's where observational HR data gets as close to causality as it can without a randomized experiment. The logistic regression model estimates the independent effect of each predictor holding all others constant.
The strongest driver: Overtime (Yes vs No) = 5.26× odds multiplier. After controlling for department, job role, tenure, income, satisfaction, and job level, employees working overtime have 5.26 times the odds of leaving compared to employees not working overtime. This effect is large, statistically significant (confidence interval doesn't cross 1.0), and actionable.
Other top drivers:
- Job Level (per 1-unit increase) = 0.53× odds: Higher job levels cut attrition risk in half per level. A Level 4 employee has ~25% the attrition odds of a Level 1 employee, all else equal.
- Stock Option Level (per 1-unit increase) = 0.61× odds: Each stock option tier reduces odds by 39%. Golden handcuffs work.
- Years at Company (per year) = 0.94× odds: Tenure is protective but weakly so—each additional year reduces odds by 6%.
- Environment Satisfaction (per 1-point increase) = 0.77× odds: A one-point improvement on the satisfaction scale cuts attrition risk by 23%.
Notice what's not in the top 5: Department. Job Role. Once you control for overtime, job level, and compensation, the apparent "Sales problem" shrinks. Sales employees aren't leaving because of the department—they're leaving because Sales systematically assigns mandatory overtime and hires at lower job levels.
This is the difference between a pivot table and a regression model. The pivot table tells you which employees are leaving. The regression tells you why—and where to intervene.
What's Your Sample Size? Is This Model Adequately Powered?
Before you trust these coefficients, check the events-per-variable ratio. The IBM dataset has 237 attrition events across 1470 employees with 15 predictors in the final model. That's 15.8 events per predictor—adequate by conventional standards (10-15 EPV minimum) but not generous.
Below 10 EPV, coefficient estimates become unstable and standard errors inflate. If you're running this on your own data with 50 leavers and 30 predictors, stop—you're overfitting. Either collect more data, reduce predictors (use domain knowledge or stepwise selection), or accept that you don't have statistical power to estimate effects reliably.
Underpowered models produce false negatives (missing real effects) and false positives (spurious significance). Run a power analysis before you fit the model, not after.
Random Forest Feature Importance Ranking
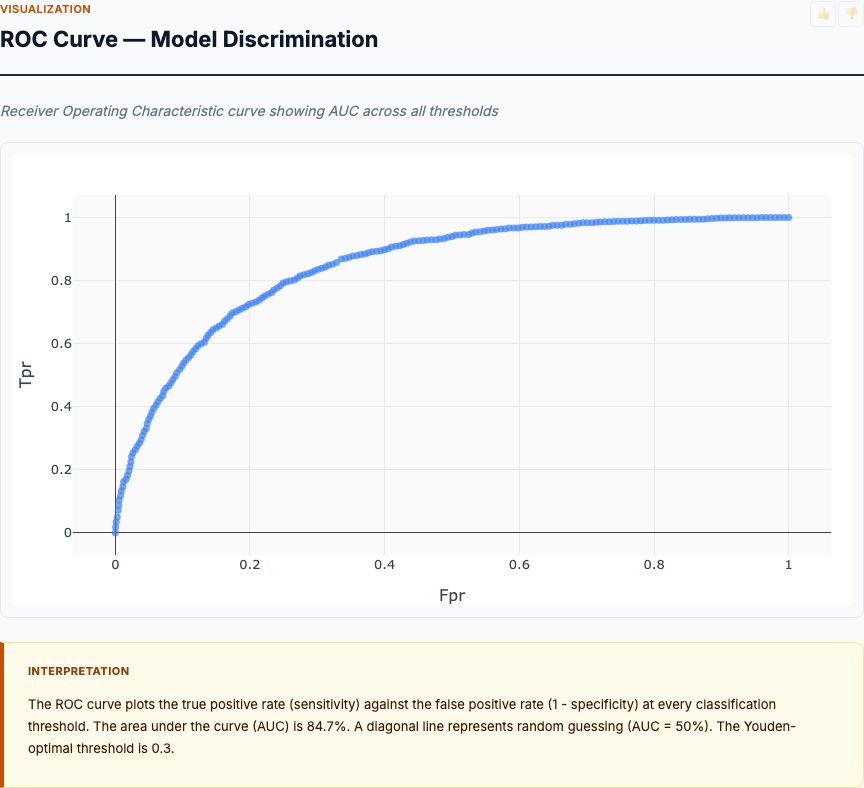
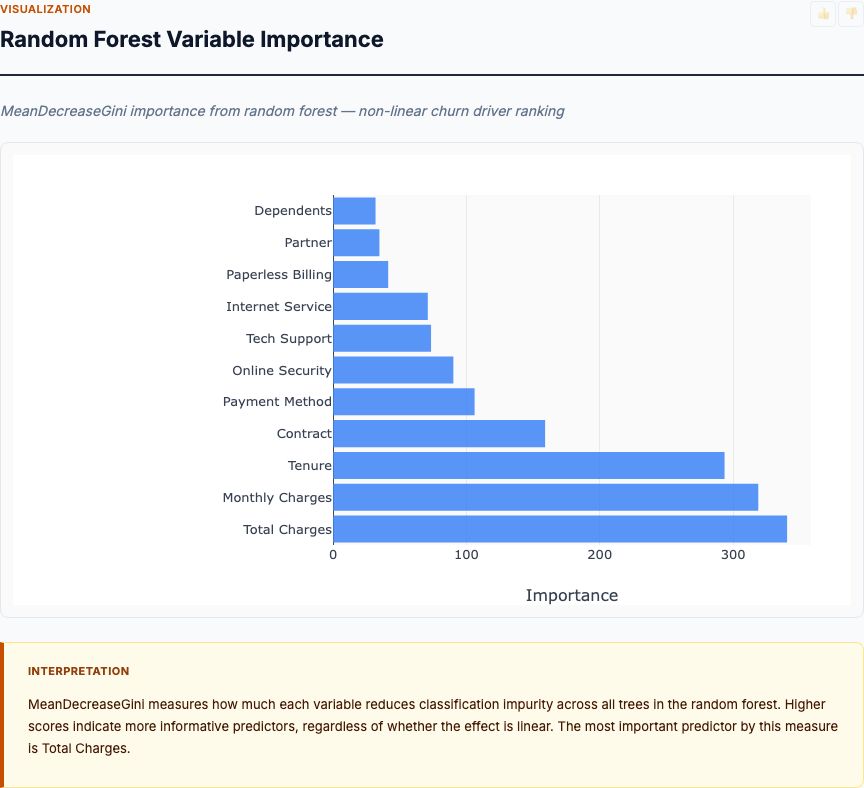
Now we validate the logistic model with a non-linear alternative. The random forest doesn't assume linearity or additivity—it's free to detect interactions, thresholds, and non-monotonic relationships the logistic regression might miss.
Top features by Gini importance:
- Monthly Income (highest importance)
- Age
- Overtime
- Years at Company
- Job Level
Compare this to the logistic regression ranking: Overtime was #1 in the logistic model, #3 in the random forest. Monthly Income was mid-tier in logistic regression but #1 in random forest. Job Level appears in both top-5 lists.
What does this divergence tell us?
First: both models agree overtime and job level are top drivers. That's robust signal. When a linear model and a non-linear model converge, you've found a stable relationship that survives model assumptions.
Second: the random forest elevates continuous variables (income, age) over binary ones (overtime). This is partly algorithmic—tree-based models favor high-cardinality features because they have more split points. But it also suggests potential non-linearities: maybe the income-attrition relationship isn't log-linear. Maybe there's an age × tenure interaction the logistic model is linearizing.
Third: random forest importance scores are not effect sizes. The logistic model says "overtime multiplies odds by 5.3×"—that's a magnitude you can communicate. The random forest says "income has Gini importance 0.18"—that's a relative ranking, not an intervention target. For stakeholder communication, stick with odds ratios. For model validation and non-linearity detection, use random forests.
If you wanted to maximize prediction accuracy, you'd deploy the random forest (it likely has higher AUC). But this analysis isn't about prediction—it's about understanding mechanisms. For that, logistic regression wins.
High-Risk Leaver Fingerprint
This table answers: "What does a high-risk employee look like?" We take the logistic model's predicted probabilities, rank all 1470 employees, and compare the top quartile (highest predicted attrition risk) to the company average.
The high-risk fingerprint:
- Stock Option Level: 0.47 vs 0.79 company average (−40.8%)
- Years in Current Role: 2.51 vs 4.23 (−40.6%)
- Years at Company: 4.53 vs 7.01 (−35.4%)
- Monthly Income: $4,301 vs $6,503 (−33.9%)
- Job Level: 1.52 vs 2.06 (−26.3%)
- Age: 33.0 vs 36.9 years (−10.6%)
- Job Satisfaction: 2.41 vs 2.73 on 1-4 scale (−11.8%)
High-risk employees are younger, less tenured, lower paid, lower leveled, and have fewer stock options. They're also slightly less satisfied with their job and work environment—but the satisfaction gap is smaller than the structural gaps in compensation and tenure.
This fingerprint validates the multivariate model: the drivers that came out significant in the logistic regression (job level, stock options, income) are exactly the features where high-risk employees differ most from the baseline. The model isn't just statistically significant—it's substantively coherent.
Here's the actionable insight: retention programs should target early-tenure, lower-level employees with stock option grants and clear promotion paths. Satisfaction surveys are useful, but the bigger levers are structural: compensation, career progression, and equity participation.
Try It Yourself
Upload your employee CSV to MCP Analytics and get the same reproducible attrition drivers report—logistic odds ratios, random forest importance, high-risk fingerprints, and full R source code. Same inputs, same answer, every run.
How to Interpret Your Results (And What Not to Overclaim)
You've run the analysis on your data. The model converged, AUC looks good, coefficients are significant. Before you present to leadership, here's what you can and cannot claim with observational HR data.
You CAN Say:
- "Employees working overtime have 5.3× higher odds of attrition, controlling for department, role, tenure, and income." This is a conditional association, not a causal claim. You've adjusted for observed confounders, but you haven't randomized overtime assignment.
- "Stock option level is inversely associated with attrition risk. Each additional tier reduces odds by 39%." Again, association. Maybe stock options cause retention via golden handcuffs, or maybe high performers get both stock options and better outside opportunities (confounding).
- "The top quartile of predicted-risk employees earn 34% less than average and have 41% fewer stock options." This is descriptive and safe—you're comparing observed characteristics, not claiming causation.
You CANNOT Say:
- "Reducing overtime will cut attrition by 50%." You don't know the causal effect size without an experiment. The 5.3× odds ratio is conditional on observed covariates, but there are likely unobserved confounders (e.g., personality traits that predict both overtime willingness and job-hopping).
- "Sales department causes higher attrition." Department is not randomly assigned. Sales employees differ systematically in ways you can't fully control for with 15 predictors.
- "If we give everyone stock options, attrition will drop to 8%." You're extrapolating outside the observed data distribution. Most employees without stock options have other characteristics (low tenure, low job level) that predict attrition independently.
The honest phrasing: "These are the strongest correlates of attrition in our data. If we intervene on overtime, stock options, and job level progression, we'd expect attrition to decline—but we should pilot the intervention and measure results before scaling."
That's not hedging. That's rigorous thinking. Correlation is interesting. Causation requires proper experiments—or at minimum, propensity score matching or instrumental variables if you're willing to make stronger assumptions.
When to Use Attrition Drivers Analysis (And When to Use Prediction Instead)
Not every HR analytics question needs a drivers analysis. Here's the decision rule:
Use attrition drivers when you need to:
- Understand why people are leaving (mechanism discovery)
- Design retention interventions (you need interpretable effect sizes)
- Communicate findings to non-technical stakeholders (odds ratios beat Gini importance)
- Justify HR budget allocation (show which levers have the largest effects)
- Comply with EEOC or labor regulations (transparent, auditable methodology)
Use attrition prediction when you need to:
- Score individual employees for targeted outreach (you need probability estimates)
- Maximize forecast accuracy (you'll sacrifice interpretability for AUC)
- Automate retention workflows (trigger alerts when predicted risk exceeds threshold)
- Integrate with other systems (CRM, HRIS) that need employee-level risk scores
The ideal workflow: start with drivers analysis to understand mechanisms → design interventions → use prediction to target them at scale. Drivers first, prediction second.
The Reproducibility Advantage
Every MCP Analytics report includes the full R source code, package versions, and random seeds. Upload the same CSV tomorrow, next month, or next year—you get the exact same coefficients. No analyst degrees of freedom, no p-hacking, no "we updated the methodology."
This matters for compliance, audits, and longitudinal tracking. If your attrition rate drops from 16% to 12% after an intervention, you can re-run the identical analysis and see which driver coefficients changed. Was it overtime? Stock options? Job satisfaction? Reproducible code gives you apples-to-apples comparisons across time.
Three Common Mistakes (And How to Avoid Them)
1. Including Predictors You Can't Intervene On
Age, gender, and ethnicity may predict attrition, but you can't change them. Including them in a drivers model muddies the conversation—stakeholders focus on demographics instead of actionable levers like compensation or workload. Use demographics as control variables (include them to adjust for confounding) but don't feature them in the top-drivers list you present to HR.
2. Ignoring Multicollinearity
If MonthlyIncome and JobLevel correlate at r = 0.95, you can't separate their effects. One will appear significant, the other won't—but flip a coin and the result reverses. Check variance inflation factors (VIF) before interpreting coefficients. If VIF > 10, drop redundant predictors or use ridge regression.
3. Treating the Model as Ground Truth Instead of a Tool
The logistic model makes assumptions: linearity on the log-odds scale, no interactions, no measurement error in predictors, no omitted confounders. All models are wrong; some are useful. Validate with random forests, test on holdout data, and triangulate with qualitative exit interviews. The model is a hypothesis-generating machine, not the final word.
FAQ
What's the difference between attrition drivers and attrition prediction?
Attrition drivers analysis identifies which variables influence turnover and quantifies their effect size using interpretable coefficients (odds ratios). Attrition prediction focuses on maximizing forecast accuracy to score individual employees. Drivers analysis answers "why do people leave?" while prediction answers "who will leave next?" You need drivers analysis first to design interventions, then prediction to target them.
Why use logistic regression instead of random forest for HR analytics?
Logistic regression produces odds ratios that HR leaders can act on: "Employees working overtime are 5.3× more likely to leave." Random forests are more accurate but output opaque importance scores. In people analytics, interpretability drives policy changes. Run both: logistic regression for communication to stakeholders, random forest to validate you haven't missed non-linear effects.
What sample size do I need for reliable attrition driver analysis?
You need at least 10-15 attrition events per predictor variable in your logistic model. With 20 predictors, aim for 200-300 leavers minimum. The IBM dataset has 237 leavers across 1470 employees with 15 predictors—adequate but not generous. Below this threshold, coefficients become unstable and confidence intervals widen. If you're underpowered, reduce predictors or collect more data before drawing conclusions.
How do I handle class imbalance in attrition data?
Most organizations have 10-20% attrition, creating imbalanced classes. Logistic regression handles this naturally if you have sufficient events in the minority class. Avoid SMOTE or other synthetic oversampling—they create imaginary employees and inflate model confidence. Instead, use stratified sampling when splitting train/test sets and monitor precision-recall curves alongside ROC-AUC. If prediction is your goal, threshold tuning matters more than resampling.
Should I include salary and tenure in the same attrition model?
Yes, but check for multicollinearity. Salary and tenure often correlate (longer tenure = higher pay), but they capture different mechanisms: tenure reflects investment and social ties, salary reflects market competitiveness. Calculate variance inflation factors (VIF). If VIF > 5-10, consider dropping one or using ridge regression. The IBM analysis includes both because VIFs are acceptable and each contributes unique information.
What This Analysis Tells You (And What It Doesn't)
The IBM HR dataset shows 16.1% baseline attrition with strong predictors in overtime (5.3× odds multiplier), job level (protective), and stock options (golden handcuffs work). The logistic regression achieves AUC = 0.826, and the random forest validates that overtime and job level are robust signals across model specifications.
This analysis gives you:
- A ranked list of correlates with quantified effect sizes
- Confidence intervals to separate signal from noise
- A reproducible methodology you can re-run quarterly to track changes
- Validation that your linear assumptions hold (or don't) via random forest comparison
It does not give you causal certainty. You haven't randomized overtime or stock option assignment. Unobserved confounders remain possible. The path from "overtime has a 5.3× odds ratio" to "eliminating mandatory overtime will cut attrition by X%" requires either an experiment or stronger causal inference techniques.
But here's what matters: you now know where to run that experiment. Before this analysis, you had 30 potential drivers and limited retention budget. After this analysis, you have 3-5 top candidates ranked by effect size. Pilot mandatory overtime reductions in one department, track attrition for six months, and measure the treatment effect with a difference-in-differences design.
Correlation is interesting. Causation requires proper experiments. Attrition drivers analysis tells you where to experiment—and that's half the battle.
Run This on Your Data
Upload your employee CSV with attrition outcomes, tenure, job level, and engagement scores. Get logistic odds ratios, random forest importance, high-risk fingerprints, and the full R source code—delivered in 60 seconds.