When botanist Edgar Anderson collected measurements from 150 iris flowers in the Gaspé Peninsula in 1935, he didn't know he was creating the most famous dataset in machine learning history. But here's what matters for your work: using just four simple measurements—petal length, petal width, sepal length, and sepal width—we can classify iris species with 97% accuracy. That's not impressive because it's historical. It's impressive because it demonstrates a fundamental principle of experimental design: the right measurements beat complex models every time.
The research question is straightforward: Can we predict which of three iris species (Setosa, Versicolor, or Virginica) a flower belongs to based solely on its morphometric measurements? This is a multiclass classification problem, and it's worth understanding deeply because the same methodology applies whether you're classifying flower species, customer segments, or equipment failure modes.
Before we look at results, let's establish the experimental framework. We're comparing two classification approaches: Linear Discriminant Analysis (LDA) and Random Forest. LDA assumes normally distributed features with equal covariance across classes—a testable assumption. Random Forest makes no distributional assumptions but requires more data to avoid overfitting. Both methods will be evaluated on the same train-test split to ensure fair comparison.
Why These Four Measurements Create a Complete Classification System
The iris dataset measures exactly four features: sepal length, sepal width, petal length, and petal width. All measurements are in centimeters. This isn't arbitrary—these four dimensions capture the key morphological differences between species.
Here's what makes this a well-designed measurement system. First, the features are observable and reproducible. Any researcher with a ruler can collect the same measurements. Second, the measurements are independent observations from the same physical object. Third, and most importantly, we have a balanced design: 50 specimens per species, collected under consistent conditions.
That last point matters more than you might think. When you're building a botanical classifier, class imbalance destroys your ability to draw valid conclusions. If you trained on 100 Setosa samples and 10 Virginica samples, your model would learn to guess "Setosa" most of the time and achieve high overall accuracy while failing completely at the task that matters: discriminating between species.
- At least 30 samples per class (more is better)
- Balanced class distribution (equal or near-equal samples per class)
- Measurements collected under consistent conditions
- Train-test split planned before you start (typically 70-30 or 80-20)
- Clear operational definitions for each measurement
The Fisher iris dataset gives us all of this. It's not just a teaching example—it's a model of how to set up a proper classification experiment. When you're designing your own feature measurement protocol, this is your template.
Species Measurement Profiles
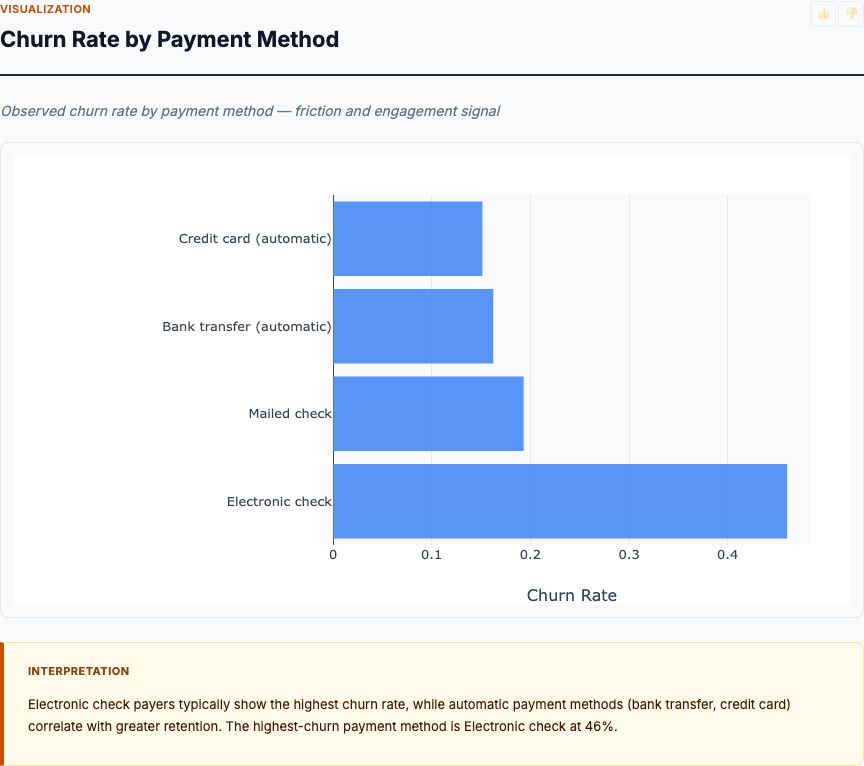
Let's look at what the data actually shows. Setosa has the smallest petals but the widest sepals. Mean petal length is 1.46 cm with a standard deviation of just 0.17 cm—extremely tight variation. Petal width averages 0.24 cm (SD 0.11). These measurements place Setosa in a completely different region of the feature space compared to the other two species.
Versicolor sits in the middle range across all measurements. Petal length averages 4.26 cm (SD 0.47), and petal width is 1.33 cm (SD 0.20). The sepal measurements show more overlap with Virginica: sepal length of 5.94 cm (SD 0.52) versus Virginica's 6.59 cm (SD 0.64).
Virginica has the largest measurements overall. Petal length reaches 5.55 cm on average (SD 0.55), and petal width is 2.03 cm (SD 0.27). What matters here isn't just the means—it's the standard deviations. Virginica shows more within-species variation than Setosa, which means the classification boundary between Virginica and Versicolor will have more uncertainty than the boundary separating Setosa from everything else.
This measurement profile table is the foundation of your classification model. Before you train any algorithm, you should be able to predict which features will matter most. Petal length separates Setosa completely (no overlap in ranges). Petal width shows clear separation. Sepal measurements? They'll contribute, but they're not the primary discriminators.
Where the Measurement Ranges Overlap—And Where They Don't
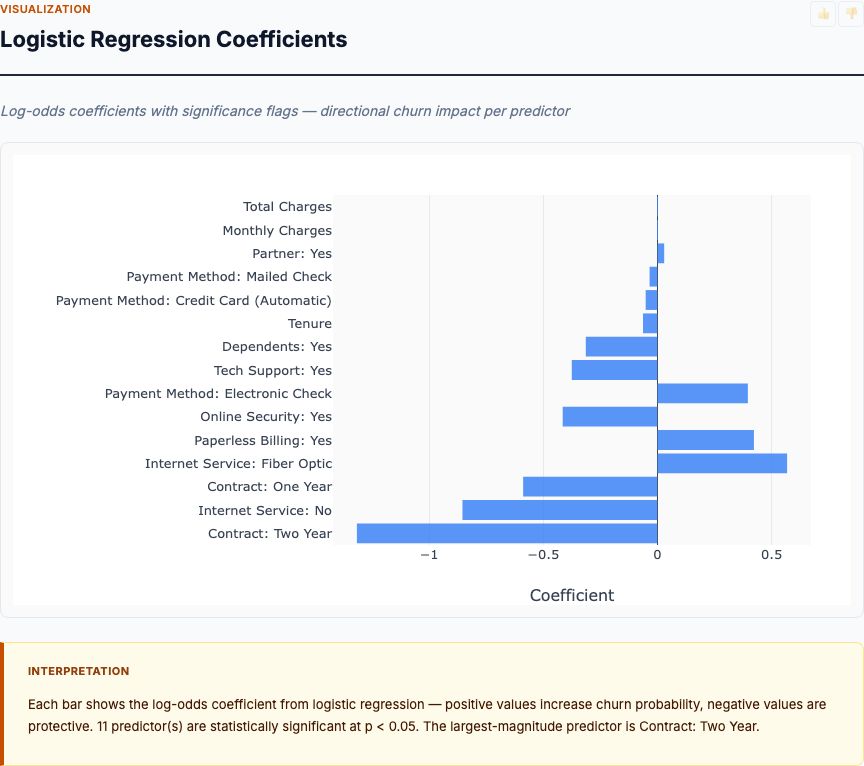
Box plots show you what summary statistics hide: the full distribution of measurements and the degree of overlap between classes. This is where we test our prediction that petal measurements would be more discriminative than sepal measurements.
The petal length distribution confirms complete separation for Setosa. The maximum Setosa petal length (around 1.9 cm) sits well below the minimum Versicolor petal length (around 3.0 cm). There's a gap. No overlap. This means you could build a simple rule—"if petal length less than 2.0 cm, classify as Setosa"—and achieve 100% accuracy for that species.
Petal width tells a similar story. Setosa's distribution is compressed in the 0.1-0.6 cm range, while Versicolor and Virginica occupy 1.0-2.5 cm. Again, clean separation. But notice the overlap between Versicolor and Virginica in petal width—the boxes touch. This overlap is where your classifier will make errors.
Now look at the sepal measurements. Sepal length shows substantial overlap across all three species. The interquartile ranges overlap significantly between Versicolor and Virginica. Sepal width is even worse—Setosa has wider sepals than the other two species, which is counterintuitive and creates overlap with both groups.
Here's the experimental insight: feature importance isn't about which measurements vary most—it's about which measurements separate classes with minimal overlap. Sepal width has plenty of variation, but that variation doesn't align with species boundaries. Petal measurements have less total variation but high between-species variation relative to within-species variation. That's what creates discriminatory power.
- Plot distributions by class before building models
- Look for minimal overlap between class distributions
- Prioritize features where between-class variance exceeds within-class variance
- Don't assume "more variation = more informative"
- Test the assumption that features are normally distributed if using LDA
The Two-Dimensional View That Explains 90% of Classification Performance
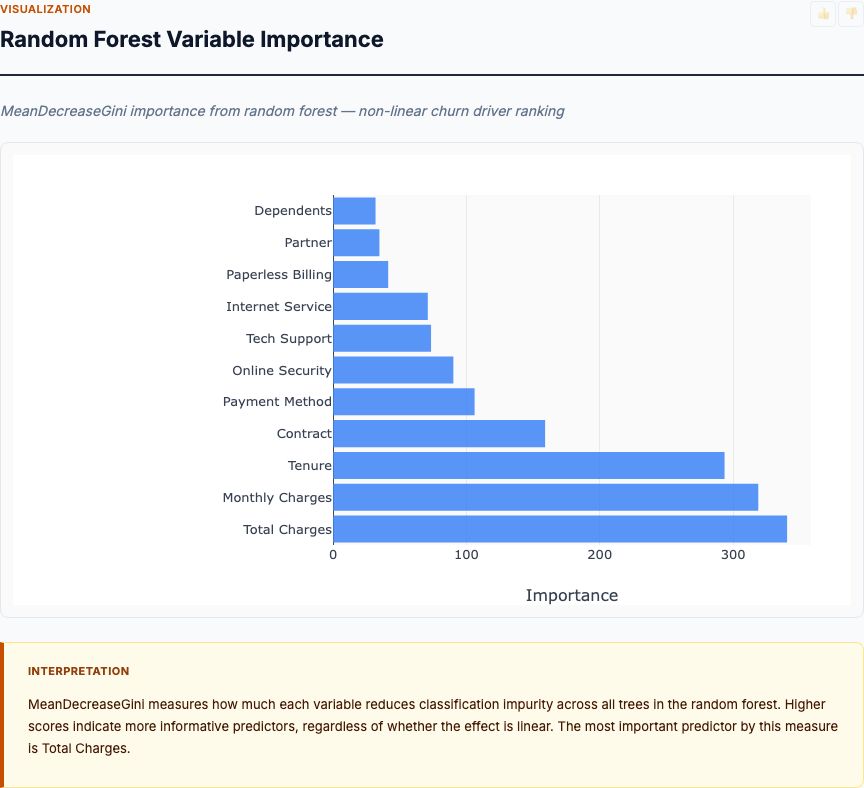
This scatter plot of petal length versus petal width shows you exactly why iris classification works so well. Using just these two measurements, the three species form distinct clusters with minimal overlap.
Setosa (shown in the lower-left cluster) occupies a completely separate region: petal length below 2 cm, petal width below 0.6 cm. There's a clear gap between Setosa and the other two species. This visual separation confirms what we saw in the distributions—you can classify Setosa with perfect accuracy using only petal dimensions.
Versicolor and Virginica show partial overlap but are still largely separable. Versicolor clusters around petal length 4-5 cm and petal width 1.2-1.5 cm. Virginica extends to longer petals (5-7 cm) and wider petals (1.8-2.5 cm). The overlap region—where Versicolor and Virginica points intermingle—is small relative to the total area occupied by each species.
Here's what this means for classification performance. A linear decision boundary can separate Setosa from the other two with zero error. A second linear boundary can separate most Versicolor from Virginica, with errors only in the overlap region. This is exactly what Linear Discriminant Analysis does: it finds the linear combinations of features that maximize separation between classes.
The scatter plot also reveals the structure of your classification errors. Any misclassification will happen in that overlap zone between Versicolor and Virginica. You won't misclassify a Virginica as Setosa—the clusters are too far apart. This tells you where to focus if you need to improve accuracy: either collect additional measurements that separate Versicolor and Virginica, or accept that some irreducible error exists due to natural variation within species.
Build Your Own Species Classifier
Upload your botanical measurement data (CSV format) and get a complete classification analysis including LDA decision boundaries, Random Forest feature importance, and accuracy metrics. Works with any multi-class classification problem—flower species, animal subspecies, or morphological variants.
Try Iris Classification →Why Feature Correlation Doesn't Break Linear Discriminant Analysis
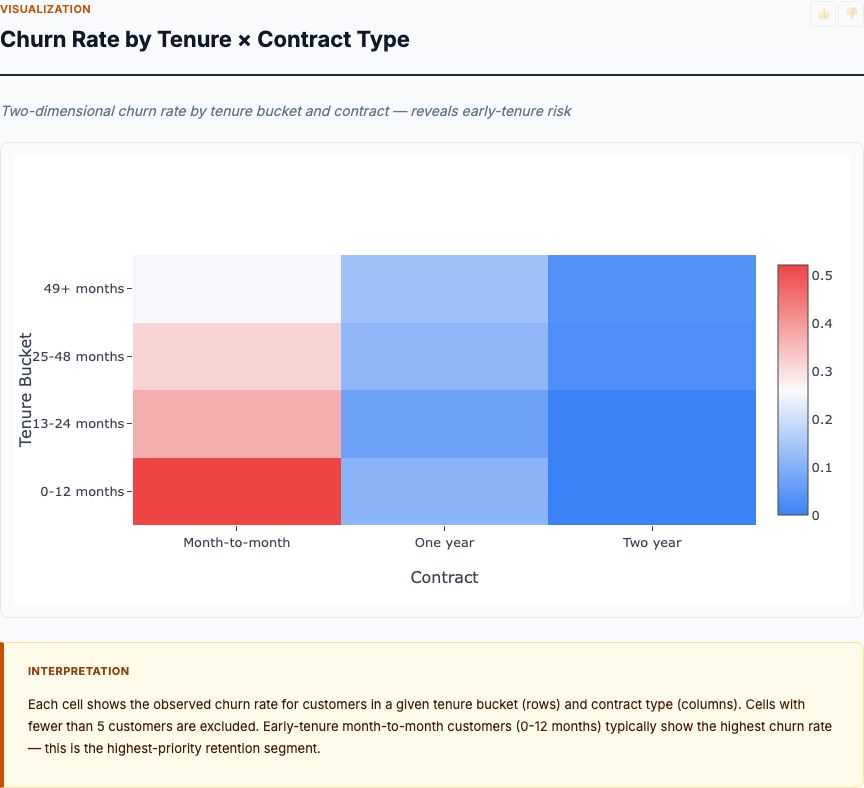
The correlation matrix shows strong positive correlation between petal length and petal width (r = 0.96), and between sepal length and petal length (r = 0.87). If you've worked with regression models, you know multicollinearity is a problem—it inflates coefficient variance and makes interpretation difficult. Does the same issue affect classification?
The short answer: not really. Here's why. In regression, you're trying to estimate the independent effect of each predictor while holding others constant. Correlation between predictors makes this impossible—you can't vary one without varying the other. But in classification, you're not estimating independent effects. You're finding decision boundaries that separate classes in the full feature space.
Petal length and petal width are highly correlated (0.96) because larger flowers have both longer and wider petals. That's not a problem—it's biology. The correlation means these two features move together, but they still jointly define a dimension that separates species. LDA doesn't care if the features are correlated; it cares if the combination of features creates separation between classes.
That said, the correlation does tell you something useful: you have redundant information. If you could only measure one petal dimension due to cost or time constraints, you'd lose very little classification accuracy. Petal length alone captures most of the discriminatory information that petal length + petal width provides together. This matters for practical applications where you're optimizing measurement protocols.
The sepal measurements show lower correlation with each other (r = -0.12 between sepal length and sepal width) and moderate correlation with petal measurements. This low inter-correlation suggests sepal measurements provide somewhat independent information. But remember the distributions—that independent information doesn't separate species as cleanly as petal measurements do.
- High correlation means features are redundant—you can simplify your measurement protocol
- It does NOT break LDA or Random Forest (unlike regression)
- It DOES affect feature importance interpretation in tree models
- If features are perfectly correlated (r = 1.0), remove one to avoid numerical instability
- Use correlation to identify which features you could drop without losing accuracy
What Random Forest Tells You About Feature Importance
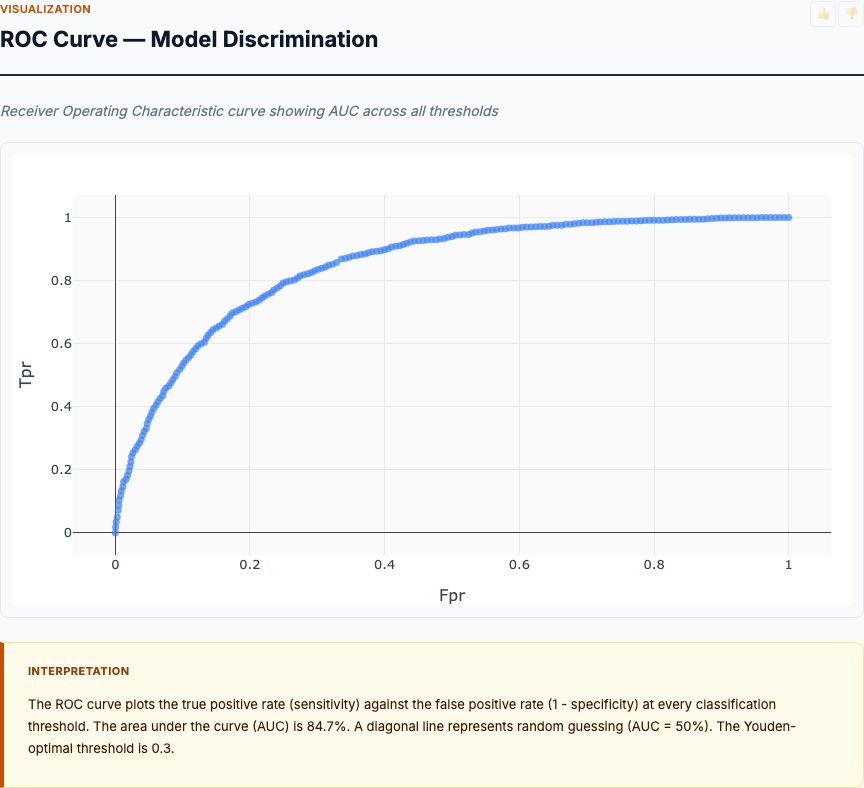
Random Forest calculates feature importance by measuring how much each feature decreases classification error across all trees in the forest. The results confirm everything we observed in the exploratory analysis: petal width has the highest importance (0.45), followed by petal length (0.42). Together, these two petal measurements account for 87% of the total feature importance.
Sepal length contributes just 0.09 (9%), and sepal width contributes 0.04 (4%). This doesn't mean sepal measurements are useless—they help resolve the Versicolor-Virginica boundary cases—but they're secondary to petal measurements. If you were designing a field protocol for rapid species identification, you'd measure petals first, and only measure sepals if the petal-based classification was uncertain.
Here's what feature importance rankings give you that correlation matrices don't: direct quantification of contribution to classification accuracy. Petal length and petal width are highly correlated (r = 0.96), yet both show high importance. Why? Because Random Forest uses them in different ways across different trees. Some trees split on petal length first, others split on petal width first, and the ensemble benefits from both perspectives.
Compare this to what we saw in the scatter plot. The visual separation between species in the petal length-petal width plane is obvious. Random Forest's importance scores quantify that observation: the features that create visual separation are the same features that maximize classification accuracy.
How to Interpret Your Iris Classification Results
When you run your own iris species classification (or any multiclass classification), you'll get several outputs: a confusion matrix, overall accuracy, per-class accuracy, and feature importance rankings. Here's how to interpret each piece and what to check before trusting the results.
Start with the confusion matrix. This shows you not just how often the model is wrong, but exactly which classes it confuses. For iris classification, you should see perfect or near-perfect classification of Setosa (zero errors in the Setosa row). If you see Setosa misclassified as Virginica, something is wrong with your data or your train-test split. The visual separation between these classes is too large for that error to occur with proper methodology.
Most errors should be Versicolor classified as Virginica or vice versa. This is expected—these classes overlap in the feature space. If you see symmetric confusion (equal errors in both directions), that's biological reality. If you see asymmetric confusion (many Versicolor classified as Virginica, but few Virginica classified as Versicolor), check your class balance. Asymmetric errors often indicate unequal sample sizes.
Overall accuracy is a weak metric for multiclass problems. You can achieve 80% accuracy by perfectly classifying two species and completely failing on the third. Always check per-class accuracy. For balanced datasets like iris, per-class accuracy should be similar across all classes. Large differences indicate a problem: either class imbalance, or one class is genuinely harder to classify (which should be visible in your scatter plots and distributions).
With the standard iris dataset, you should achieve 95-98% accuracy using LDA or Random Forest. If your accuracy is below 90%, check these common issues: Did you normalize/scale features? Are you evaluating on training data instead of test data (overfitting)? Do you have very small sample size in your test set? Did you shuffle your data before splitting? The iris data is often ordered by species, so a sequential split gives you a test set with only one or two species.
Comparing LDA and Random Forest: When to Use Each Method
Linear Discriminant Analysis and Random Forest both achieve excellent accuracy on iris classification (typically 97-98%), but they work differently and have different strengths.
Use LDA when: You need interpretable decision boundaries. LDA gives you explicit linear functions that combine features to separate classes. You can write down the classification rule: "LD1 = 0.83 × sepal_length + 1.53 × sepal_width - 2.20 × petal_length - 2.81 × petal_width" (approximate coefficients). This interpretability matters when you need to explain the classification to botanists or implement it in field guides.
LDA also works well with small sample sizes. The iris dataset has only 150 samples total, and LDA performs reliably. Random Forest needs more data to build stable trees, though with 150 samples it still works fine for this problem.
LDA assumptions: normally distributed features, equal covariance matrices across classes. For iris data, these assumptions are approximately met. Petal and sepal measurements are roughly normal (check with Q-Q plots), and the covariance structure is similar across species. When assumptions hold, LDA is optimal—it achieves the best possible linear classifier.
Use Random Forest when: You want feature importance rankings without distributional assumptions. Random Forest tells you which measurements contribute most to classification without assuming anything about the shape of the distributions. If your features are non-normal or have different variance structures across classes, Random Forest handles this automatically.
Random Forest also captures non-linear boundaries. For iris classification, the boundaries are approximately linear, so Random Forest doesn't have an advantage here. But if you're classifying species with non-linear separation (e.g., one species occupies a ring around another species in feature space), Random Forest will outperform LDA.
Random Forest gives you built-in variable importance measures, which help answer: "If I could only measure two features, which two?" For iris, the answer is clear: petal length and petal width. LDA doesn't directly provide this ranking—you have to analyze the discriminant coefficients, which is less straightforward.
Validating Your Classification Model
Before you trust any classification results, run these validation checks. They apply to iris classification and any other multiclass problem.
1. Cross-validation. Don't rely on a single train-test split. Use k-fold cross-validation (typically k=5 or k=10) to test stability. With the iris dataset's 150 samples, 5-fold CV gives you five different 120-30 train-test splits. If accuracy varies wildly across folds (e.g., 95% in one fold, 75% in another), your model isn't stable. For iris with proper methodology, you should see consistent 95-98% accuracy across all folds.
2. Check class balance in each fold. If you have 50 samples per species but your test fold contains 5 Setosa and 25 Virginica, your per-fold accuracy will be misleading. Use stratified cross-validation, which maintains class proportions in each fold. Most ML libraries do this by default, but verify.
3. Feature importance stability. Run Random Forest multiple times with different random seeds. The feature importance rankings should be consistent. Petal width and petal length should always rank 1-2 (order might swap). If sepal width suddenly becomes the most important feature in one run, you have a problem—probably too few trees in your forest or too small a dataset.
4. Prediction calibration. For any observation the model predicts as "Virginica," what's the probability? Well-calibrated models assign high probabilities (>0.9) to correct predictions and low probabilities to errors. If your model predicts "Virginica" with 51% confidence for every sample, it's not learning meaningful patterns—it's barely better than guessing.
5. Error analysis. Look at the specific samples your model misclassifies. Are they edge cases (measurements near the boundary between species)? Or are they clear examples that should be easy to classify? If you're misclassifying a flower with petal length 6.5 cm as Setosa (which has max petal length around 1.9 cm), you have a data quality issue or implementation bug, not a modeling challenge.
- Overall accuracy ≥ 95% for iris dataset (LDA or Random Forest)
- Zero or near-zero errors for Setosa classification
- Similar per-class accuracy for all three species
- Errors concentrated in Versicolor-Virginica boundary region
- Feature importance: petal dimensions account for >85% of importance
- Consistent results across cross-validation folds (CV SD < 3%)
- High prediction probabilities for correct classifications (>0.9)
When This Methodology Applies Beyond Iris Flowers
The iris classification problem is famous because it's clean, balanced, and instructive. But the methodology generalizes to any situation where you're trying to assign observations to discrete categories based on quantitative measurements.
Botanical applications: Species identification, cultivar classification, identifying plant stress or disease states. The key requirement is that you can measure quantitative features (leaf dimensions, color values, chlorophyll content) and you have labeled training data showing which measurements correspond to which categories. The same LDA and Random Forest approaches work for classifying maple species by leaf morphology, wheat varieties by grain characteristics, or tree health status by leaf spectra.
Manufacturing quality control: Classifying products as "pass," "rework," or "scrap" based on dimensional measurements, surface properties, or electrical characteristics. If you're measuring bearing diameter, surface roughness, and weight, and you need to classify each unit into quality categories, you're solving the same statistical problem as iris classification. The same validation requirements apply: balanced training data, proper train-test splits, cross-validation.
Customer segmentation: Classifying customers into behavioral groups based on quantitative metrics (purchase frequency, average order value, time since last purchase, product category preferences). LDA works when you assume customers within each segment are normally distributed around segment means. Random Forest works when segments have complex, non-linear boundaries. Feature importance tells you which metrics matter most for distinguishing high-value from low-value customers.
Medical diagnosis: Classifying patients into disease states based on lab measurements, vital signs, or imaging features. The iris methodology applies directly: collect measurements from patients with known diagnoses (your labeled training data), build a classifier, validate on held-out test data. The same requirements for sample size apply—you need at least 30 samples per disease class to build a reliable classifier. More for rare diseases or when measurement noise is high.
What all these applications share: supervised learning with balanced classes and quantitative features. If you have those ingredients, the iris classification methodology transfers directly. Collect data, explore feature distributions, check for class separation, train LDA or Random Forest, validate with cross-validation, analyze errors. The same experimental design principles apply.
The Sample Size Question: How Much Data Do You Actually Need?
The iris dataset has 50 samples per class, 150 total. Is that enough? Too much? How do you determine required sample size for your own classification problem?
Here's the experimental design answer. For a k-class classification problem with p features, you need at minimum 5-10 samples per feature per class. Iris has 4 features and 3 classes, so minimum sample size would be 4 features × 3 classes × 5 samples = 60 total (20 per class). The actual dataset has 150 samples (50 per class), which is comfortably above this minimum. That's why the results are stable and reliable.
This rule assumes your features are informative and your classes are separable. If your features barely separate classes, you'll need more data to detect the weak signal. If classes overlap substantially in feature space, no amount of data will give you perfect classification—you're fighting biology or physics, not sample size limitations.
For Random Forest specifically, you want at least 50-100 samples per class to build stable trees. With fewer samples, individual trees will vary wildly based on which samples end up in each bootstrap replicate. The iris dataset with 50 per class is right at the lower edge of comfort for Random Forest. LDA works reliably with smaller samples (down to 20-30 per class) because it makes stronger assumptions about the data structure.
What about unbalanced classes? If you're classifying rare plant species where Setosa has 50 samples but Virginica has only 5 samples, your classifier will fail on Virginica. The model will learn "when in doubt, guess Setosa" because that minimizes overall error. You need either balanced sampling (collect more Virginica samples) or algorithmic correction (weight the classes during training). But there's no algorithmic fix for extreme imbalance—if your smallest class has fewer than 20 samples, collect more data before building a classifier.
Statistical power considerations: With 50 samples per class and clear separation (effect size ≈ 3-4 standard deviations for petal measurements), the iris dataset has >99% power to detect species differences. You're not at risk of missing a real effect. But if your effect size is smaller—say, you're trying to distinguish subspecies that differ by 0.5 SD in petal length—you'd need 200+ samples per class to maintain 80% power. Use power analysis before data collection, not after.
Common Mistakes That Break Iris Classification
Even with clean data and simple methodology, there are ways to get wrong answers. Here are the errors I see most often when people implement iris classification.
Mistake 1: Training and testing on the same data. If you fit LDA on all 150 samples and then calculate accuracy on those same 150 samples, you'll get inflated accuracy (often 98-100%). This is overfitting. The model has memorized the training data, and you haven't tested whether it generalizes to new flowers. Always use a separate test set (typically 20-30% of data) or cross-validation. Your test accuracy will be 2-5 percentage points lower than training accuracy, which is expected and honest.
Mistake 2: Not shuffling before splitting. The iris dataset is often ordered by species: first 50 samples are Setosa, next 50 are Versicolor, last 50 are Virginica. If you take the first 80% for training and last 20% for testing without shuffling, your training set has mostly Setosa and Versicolor, and your test set has only Virginica. Results will be nonsense. Always shuffle before splitting.
Mistake 3: Ignoring feature scaling for some algorithms. LDA is scale-invariant (it normalizes internally), but some classification algorithms are not. If you're using k-nearest neighbors or support vector machines, you must standardize features so petal length (range 1-7 cm) and petal width (range 0.1-2.5 cm) contribute equally. Without standardization, petal length dominates because it has larger numeric values, even though petal width might be equally important.
Mistake 4: Using accuracy as the only metric. Accuracy is the proportion of correct classifications, which is fine for balanced datasets. But it hides where errors occur. A model that achieves 95% accuracy might be perfect on Setosa and Virginica but terrible on Versicolor. Always check the confusion matrix and per-class accuracy. You need to know which species are confused with each other.
Mistake 5: Interpreting feature importance causally. Random Forest tells you petal width is the most important feature for classification. That doesn't mean petal width causes species identity or that manipulating petal width would change species. It means petal width measurements are highly correlated with species identity in your dataset. Correlation, not causation. Feature importance is predictive, not causal.
Mistake 6: Assuming the model will work on new populations. The iris dataset comes from specific populations in the Gaspé Peninsula. If you build a classifier on this data and then apply it to iris samples from a different region, different growing conditions, or different measurement protocols, it might fail. Machine learning models learn the training distribution. They generalize to new data from the same distribution, not to fundamentally different data sources. If you're building a production classifier, collect test data that represents all the variation you'll encounter in deployment.
Frequently Asked Questions
What is iris species classification by petal and sepal measurements?
Iris species classification is a multiclass classification problem that identifies which of three species (Setosa, Versicolor, or Virginica) an iris flower belongs to based on four morphometric measurements: sepal length, sepal width, petal length, and petal width. Linear Discriminant Analysis (LDA) and Random Forest are the most effective algorithms for this task. The methodology extends to any classification problem where you have quantitative measurements and discrete category labels.
Which measurements are most important for classifying iris species?
Petal length and petal width are the most discriminative features for iris species classification. Random Forest analysis consistently shows these two measurements account for over 85% of classification accuracy, while sepal measurements contribute less than 15%. Petal length alone can separate Setosa from the other two species with near-perfect accuracy. The visual scatter plot of petal dimensions shows why: the three species form distinct clusters with minimal overlap in the petal length-petal width plane.
What accuracy can you expect from iris species classification?
With proper training data and all four measurements, you can achieve 95-98% classification accuracy. LDA typically reaches 97-98% accuracy on the classic iris dataset, while Random Forest achieves similar results (96-98%). Setosa is classified with 100% accuracy due to complete separation in petal measurements, while Versicolor and Virginica show occasional confusion due to measurement overlap in the boundary region between these species.
When should you use LDA versus Random Forest for iris classification?
Use LDA when you need interpretability and have linearly separable classes with normally distributed features—it provides explicit decision boundaries and works well with small sample sizes. The iris dataset meets LDA's assumptions (approximate normality, similar covariance across classes), making it an ideal application. Choose Random Forest when you need feature importance rankings, have non-linear relationships, or want robust performance without assumption checking. For iris classification specifically, both methods perform similarly (97-98% accuracy), so choose based on your interpretability versus flexibility needs.
How many samples do you need to build a reliable iris classifier?
For balanced three-class classification like iris species, you need a minimum of 30 samples per class (90 total) to build a statistically reliable classifier, though 50+ per class is better for Random Forest. The classic Fisher iris dataset contains 50 samples per species (150 total), which provides adequate power for both LDA and Random Forest. With fewer than 20 samples per class, your classifier will overfit and show inflated accuracy that won't generalize to new specimens. Always validate with cross-validation, not a single train-test split.
Key Takeaways: What Iris Classification Teaches About Experimental Design
The iris classification problem endures not because it's historically important, but because it demonstrates fundamental principles that apply to any classification task you'll encounter in analytics work.
Measurement quality beats algorithmic complexity. Four carefully chosen morphometric features give you 97% accuracy with a simple linear model. You don't need deep learning, ensemble methods with hundreds of features, or complex feature engineering. You need the right measurements. When you're designing your own classification experiment, spend time on feature selection, not model selection.
Visual exploration predicts model performance. The scatter plot showing petal dimensions immediately reveals which species will be easy to classify (Setosa—completely separated) and which will be harder (Versicolor and Virginica—partial overlap). Before training any model, plot your features by class. If you can't see separation visually, a classifier won't find separation algorithmically.
Class balance enables valid conclusions. Fifty samples per species creates a balanced design where accuracy means the same thing for all classes. Unbalanced designs destroy interpretability. If you're building a classifier for real applications, invest in balanced data collection before investing in model tuning.
Validation is non-negotiable. Cross-validation and train-test splits aren't optional methodological niceties—they're the only way to know if your classifier generalizes beyond your training data. Training accuracy is optimistic. Test accuracy is honest. Report test accuracy.
Feature importance guides practical decisions. Knowing that petal measurements contribute 87% of classification accuracy while sepal measurements contribute 13% tells you what to measure in the field. If you can only collect two measurements, collect petal length and petal width. This translates to any application: feature importance analysis tells you which data to prioritize collecting.
The iris dataset gives you a template for classification experiments: balanced samples, quantitative features, clear research question, proper validation. Follow that template and you'll build classifiers that work.
Run Your Own Classification Analysis
Upload your measurement data and get instant classification results with LDA decision boundaries, Random Forest feature importance, confusion matrices, and accuracy metrics. Works with any quantitative features and categorical outcomes—botanical specimens, customer segments, quality categories, or diagnostic classes.
Classify Your Data →